In this notebook we use random forests, which is a machine learning technique built upon decision trees. Furthermore, we use the fastai(Howard and Gugger 2020) library to download the data for the different tasks and easily train our models.
1 Introduction
Tabular data or structured data problems are pretty common in the field of machine learning. It is the prototypical problem in which each sample is described by a certain set of features and, thus, the dataset can be layed out in a table (hence the name). The goal, then, is to predict the value of one of the columns based on the rest. Up until quite recently, tabular data problems where generally addressed with classical models based on decision trees, be it ensembles or gradient boosted machines. However, deep learning has proven quite successful on these tasks in the past years.
Within this field, we encounter problems of all kinds, from telling flower types apart given a feature list, to assessing whether to give a loan to a bank client. Unfortunately, tabular data problems are much less nicer to show than computer vision tasks and so this part will be less flashy than the others. In order to illustrate the process, we will address a regression problem to infer the auction prices of bulldozers that was a kaggle competition. We will solve the same problem with random forests and neural networks in order to see what differences we find with them.
Note
We take a regression example here, but tabular data problems can also be classification tasks and all the processes shown may be applied indistinctively.
The first thing to do is to identify our target value. In this case, it is the SalePrice column and, in fact, we want to predict the logarithm of the price, as stated in the competition. Then, these problems heavily rely on feature engineering, which consists on adding additional (smart) features that may be informative for the task. For instance, from a single date we can extract the day of the week, whether it was weekend or holidays, beginning or end of the month, etc. We could even figure out the weather if needed!
Competitions such as this one are won, in general, by those who can come up with the best relevant features for the task at hand.
Generally, besides feature engineering, one of the key points in this kind of problems is properly handling categorical and numerical values as well as missing values. For instance, ProductSize is a categorical feature which takes values ‘Large’, ‘Large / Medium’, ‘Medium’, ‘Small’, ‘Mini’ and ‘Compact’. The model does not konw how to process these strings and so we convert them into numerical values assigning a number to each category. These numbers have essentially no meaning. However, given the nature of decision trees, it is convenient that ordinal categories, such as this one, are ordered so that increasing numbers, for example, represent increasing categorical sizes. Numerical values, in turn, should be properly normalized (for neural networks) and, finally, missing values are filled with the mean value of the column and a new column indicating wether it was filled or not is added.
Choosing the right validation set is also extremely important. Given that this is a price forecasting task, we will take the latest sales within the training dataset to be our validation set.
Random forests are the go-to technique to deal with tabular data. They are extremely powerful and extremely easy to set up and train thanks to libraries like sci-kit learn.
The RMSE is 0.23 in the logarithm of the price. Let’s see how to improve on this. Random forests are quite easy to interpret and we can see, for instance, what are the most relevant features as well as those that are redundant.
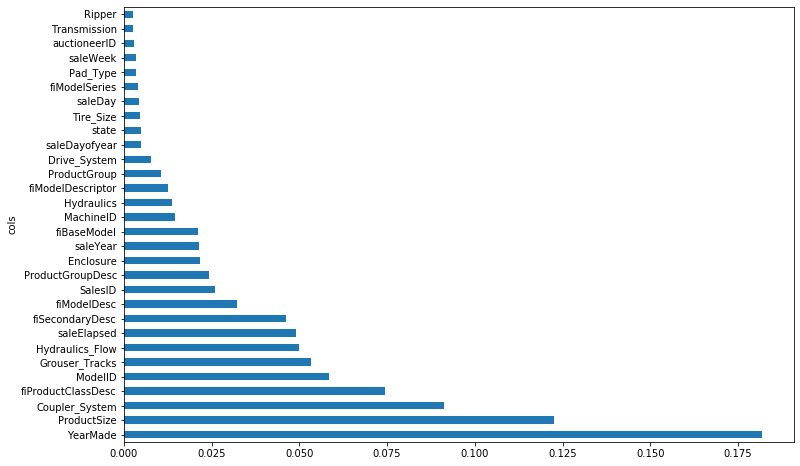
Let’s have a look at the feature importances of the most significant ones (top 30).
We can see that some features are much more relevant than others. For instance, the year in which the bulldozer was made and its size seem to be the most significant aspects when it comes to determining its selling price, while things such as the transmission mechanism or the day it is being sold barely have an impact.
We will remove the least relevant features and retrain our model, leading to a simpler regressor. Therefore, if the performance is similar, it means that it will be able to generalize better. Evaluating the RMSE of the retrained model in the validation set we see that it is not only similar but, actually, a little bit better.
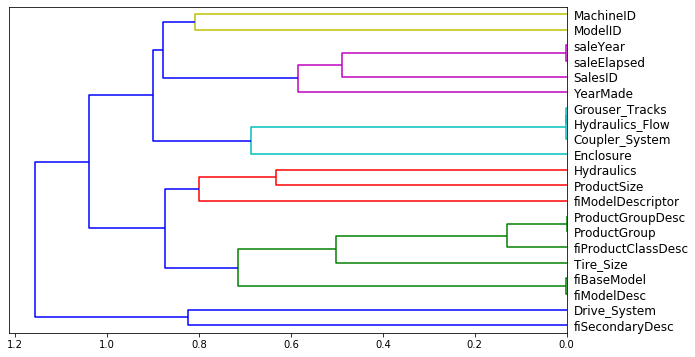
Besides feature importance, we can also see which of these features are redundant or provide similar information. Removing redundant features makes our model simpler and more robust, meaning that it will generalize better to unseen data.
Those features that are merged together at the rightmost part of the plot are the ones that are the most similar. For instance, ‘SaleYear’ and ‘SaleElapsed’ provide the same information but in different formats: the first states the year it was sold and the second tells us how many years have passed since it was sold. Just like with irrelevant features, we can remove some of these redudant ones and re-evaluate our model.
Dropping the least informative features and some of the redundant ones, we have greatly simplified our model while keeping the same performance. This will allow the model to generalize much, much better. We could keep up with the model interpretation and feature engineering, but it is beyond the scope of this lesson. Some other features that we can drop are time-stamp variables, such as MachineID and SalesID, as well as some model identification ones. This is because, with the model in production, when we want to infer the price of a bulldozer that is currently being sold, the time-stamp-related features do not provide any significant information to the random forest, provided that it is completely unable to generalize beyond what it has seen during training. For an in-depth explanation, check the lesson 7 of fastai’s 2020 course.
We will proceed now to do the prediction by training a neural network.
3 Neural networks
While random forests do great work, they are completely unable to extrapolate to regions beyond the limits of the training data. It may not be the end of the world for some tasks, but it is definitely terrible for some others.
However, as we have seen, those models can be extremely helpful to understand the data and get an idea of the most important features, as they are very easily interpretable. Therefore, we will combine both approaches and take advantage of the feature analysis that we have performed with the random forest. This way, we will get rid of some of the meaningless features straight away before training the network.
Expand to learn about the training details
The neural network will have to deal with continuous and categorical variables in a completely different way. We will create an embdedding for each categorical variable, while the numerical ones are just input into a fully connected layer. Then, everything is brought together in a dense classifier at the end. Therefore, it is importnat that we split the variables into numerical and categorical and, in fact, categorical variables with high cardinality, like saleElapsed, may be dealt with as numerical ones to prevent massive embeddings.
In order to compare the random forest with the neural network we have to check what the RMSE is.
Code
preds,targs = learn.get_preds()r_mse(preds,targs)
0.226801
The neural network provides a much better result than the random forest predicting the sales price of bulldozers. This is, mainly, due to the hard limitation in extrapolation of random forests, which make them struggle in forecasting tasks such as this one where prices evolve through time and we have to make inferences in the future.
This has been only one example of how to apply machine learning to tabular data. As you can see, these kind of problems offer a much more engaging relationship in the feature engineering part, provided that we feed the data straight into the classifier.