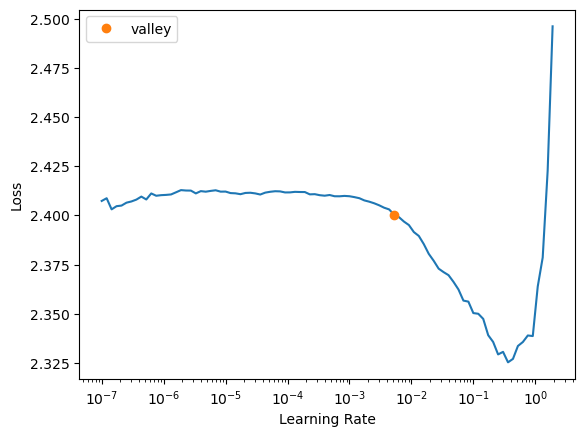
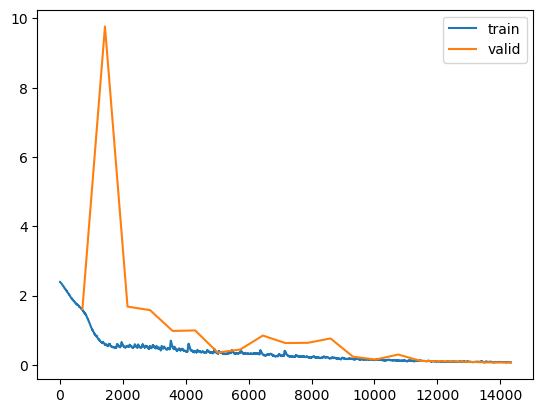
(tensor([[10, 3, 7, ..., 3, 7, 8],
[ 0, 7, 6, ..., 7, 9, 10],
[ 2, 4, 6, ..., 4, 6, 7],
...,
[ 2, 4, 8, ..., 4, 8, 5],
[ 6, 2, 8, ..., 2, 8, 7],
[ 9, 10, 3, ..., 10, 3, 5]], device='cuda:0'),
tensor([ 9, 8, 0, 7, 3, 10, 6, 6, 0, 5, 0, 4, 9, 5, 10, 8, 5, 2,
5, 7, 6, 5, 4, 1, 3, 9, 8, 7, 2, 10, 10, 7, 5, 1, 6, 4,
10, 3, 1, 0, 8, 10, 8, 6, 5, 2, 0, 9, 6, 7, 9, 8, 0, 7,
7, 9, 6, 9, 1, 1, 5, 5, 3, 10, 3, 9, 2, 10, 3, 7, 3, 3,
6, 7, 4, 2, 1, 1, 0, 7, 7, 1, 7, 9, 1, 2, 3, 6, 6, 7,
9, 1, 5, 9, 0, 10, 10, 7, 10, 6, 3, 8, 2, 5, 5, 3, 1, 10,
3, 7, 2, 10, 10, 3, 6, 3, 5, 1, 2, 0, 7, 0, 5, 4, 8, 10,
9, 9], device='cuda:0'))